MetroLab’s Executive Director Ben Levine interviewed Bill Howe, associate professor at the Information School at the University of Washington, and Julia Stoyanovich, assistant professor of computer science at the College of Computing and Informatics at Drexel University, to explore their DataSynthesizer — a.k.a. “Fake Data” — for social good project.
Ben Levine: Could you please describe what the DataSynthesizer project is? Who is involved in this project?
Bill Howe: Data scientists need access to data to do anything useful. Municipal data providers must be careful about how, when and why they share data. If they're not, they risk violating the trust of the people they aim to help, losing their funding or breaking the law. Data sharing agreements can help prevent privacy violations, but they require a level of specificity in the research task that is often premature for exploratory collaborations and often take over a year to establish. We consider the generation and use of synthetic data a critical ingredient in facilitating ad hoc collaborations involving sensitive data.
A good fake data set has two properties: It is representative of the original data and it provides strong guarantees against privacy violations. The DataSynthesizer project is about developing practical, usable tools to satisfy these requirements, using state-of-the-art methods in privacy protection.
The initial tool, developed by Haoyue Ping, takes a tabular sensitive data set as the input and generates a structurally and statistically similar synthetic data set with strong privacy guarantees as the output. The data owners do not need to release their data, while potential collaborators can begin developing models and methods with some confidence that their results will work similarly on the real data set. The distinguishing feature of DataSynthesizer is its usability — the data owner does not have to specify any parameters to start generating and sharing data safely and effectively.
Levine: Can you describe what this project focused on and what motivated you to address this particular challenge?
Howe: The project began as a practical solution to a specific problem. The computer science research teams at University of Washington and Drexel University, our sponsor, the Bill and Melinda Gates Foundation, and King, Pierce, and Snohomish counties in Washington state were interested in sharing homelessness data — and we wanted to expand the collaboration with additional faculty and students, but we could not freely share the data.
Julia Stoyanovich: One of the strongest sources of motivation in our work, on this project and others, is to bridge the gap between data science research and practice. That is, our research is translational in nature — we are not satisfied solely by proving theorems and publishing papers in computer science research venues. Rather, we want to see our results be used by practitioners. Privacy, and in particular differential privacy, has attracted considerable research attention, but produced few usable tools. Our work was motivated by the need to fill this translational gap. Howe: Since its development, the tool has been receiving a lot of attention. For example: T-Mobile is interested in generating synthetic data to better engage with researchers and improve transparency for customers, the Colorado Department of Education has asked relevant agencies to use the tool to experiment with sharing sensitive data, and Elsevier is interested in using the tool to generate synthetic citation networks for research.
Differential PrivacyDifferential privacy has become the dominant standard for controlling the disclosure about individuals that results from analyzing a sensitive database. In the standard differential privacy setting, individuals contribute sensitive information to a private database, managed by a trusted data collector. Untrusted analysts may interact with the database by submitting queries, or requesting synthetic data, which triggers processing by an algorithm that adds noise to guarantee privacy of individuals at the expense of accuracy. — Julia Stoyanovich |
Howe: As Julia suggests, we consider this tool, and the overall approach, an example of "translational" research, where the research questions emerge only from working directly with partners. Although there is a rich body of work on synthetic data generation, there has been essentially no research into the system’s questions that emerge in practice. For example, a "raw" .csv file does not carry with it any metadata describing the allowed domain of values, but most of the methods described in the literature assume a fixed, known domain to ensure privacy. We had to adapt these methods to ensure the same guarantees.
Levine: There are sometimes concerns in the public sector that go beyond just data-sharing — one that we recently explored at MetroLab is the use of predictive analytics in human services. Are these concerns justified?
Stoyanovich: Government agencies have no choice but to work with data: The reality of today's technological landscape demands it! In the case of predictive analytics, data is used to customize algorithm behavior — this is called “training." The same algorithm may exhibit radically different behavior — make different predictions, or make a different number of mistakes, and even different kinds of mistakes — when trained on two different data sets. In other words, without access to training data, we cannot know how a predictive analytics method will actually behave. Algorithms of this kind are used, for example, in predictive policing software.
Other decision-making algorithms, including, for example, scoring methods like the Vulnerability Index - Service Prioritization Decision Assistance Tool (VI-SPDAT), which is used to prioritize homeless individuals for receiving services, and matchmaking methods such as those that assign children to spots in public schools, do not explicitly attempt to predict future behavior based on past behavior. Yet these algorithms also rely on data in important ways: They are designed and validated using data.
On Oct. 16, I had the privilege of testifying before the New York City Council Committee on Technology regarding a proposed bill on algorithmic transparency. In my testimony, I argued that meaningful algorithmic transparency cannot be achieved without data transparency. One immediate interpretation of this principle involves making the training and validation data sets publicly available. However, while data should be made open whenever possible, much of it is sensitive and cannot be shared directly. That is, data transparency is in tension with the privacy of individuals who are included in the data set.
Instead, a reasonable data transparency method is to make publicly available summaries of statistical properties of the data sets, while using state-of-the-art methods to preserve the privacy of individuals. When appropriate, privacy-preserving synthetic data sets can be released in lieu of real data sets, if real data sets are sensitive. Our DataSynthesizer tool, its extensions and other tools of this kind can be used for this purpose.
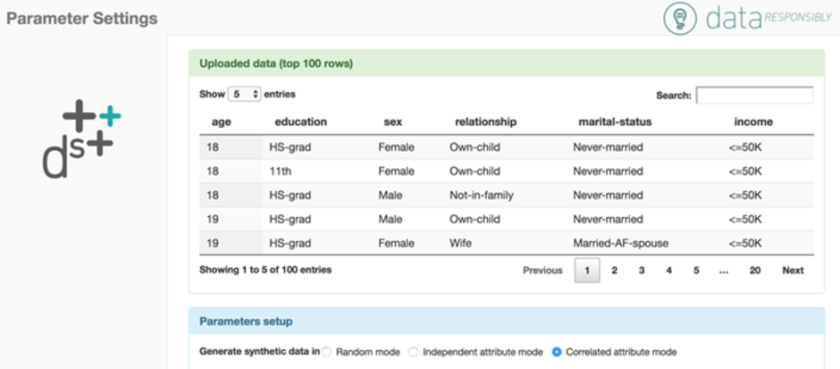
The Data Synthesizer tool is invoked by the data owner. The tool produces a summary of the (real) sensitive data set, adds noise to the summary to preserve privacy and then generates a synthetic data set from the noisy summary. This screenshot shows the first five entries in the sensitive data set to give some context, and prompts the user to select a data generation mode for synthetic data. Courtesy of Julia Stoyanovich.
Levine: Where will this project go from here?
Howe: We are now exploring how to create synthetic data for more complex situations and data types: trajectories, evolving graphs, linked data from multiple sources and large scale data sets.
The benefits of this approach are that the business of designing solutions that guarantee differential privacy tend to be very application-specific. In other words, different types of questions need customized solutions.
In our world of synthetic data, we are making some assumptions about the input: that each record is a person and that the relationships between attributes follow one of a couple of models we support.
But for more complex data, such as mobility data from a ride-share service, each record might be a GPS position. So to protect the privacy of a person who generates those positions, you need a different approach.
We envision a suite of tools that can handle lots of different kinds of data, but we need to develop each of these carefully. Other complications can arise from the need to generate synthetic data in parallel to emulate very large datasets. In all cases, our emphasis is on practical tools with strong guarantees, so we want to "take whatever is thrown at us."
More broadly, we envision synthetic data generation as a component of a larger platform for responsible data management that we call “Fides,” which will be designed to support fairness and transparency features, hypothesis management, usage policy enforcement, auditing, and more, in addition to a core data management and query facility. We want to provide a software infrastructure that enables smaller agencies and NGOs to have access to state-of-the-art analytical methods without violating the trust of their stakeholders.
Additional information about our work is available at dataresponsibly.com.
About MetroLab: MetroLab Network introduces a new model for bringing data, analytics and innovation to local government: a network of institutionalized, cross-disciplinary partnerships between cities/counties and their universities. Its membership includes more than 35 such partnerships in the United States, ranging from mid-size cities to global metropolises.These city-university partnerships focus on research, development, and deployment of projects that offer technologically and analytically based solutions to challenges facing urban areas including: inequality in income, health, mobility, security and opportunity; aging infrastructure; and environmental sustainability and resiliency. MetroLab was launched as part of the White House’s 2015 Smart Cities Initiative. Learn more at www.metrolabnetwork.org or on Twitter@metrolabnetwork.






